
Meteor Impact 2021
ℹ️ These are just personal notes that supplement the talks. They may not make perfect sense without seeing the talks themselves.
Disclaimer: I'm new to Meteor, so mistakes are possible probable.
- https://www.reddit.com/user/radekmie
- https://radekmie.github.io/blog
- https://github.com/radekmie
- Radek is consultant for generic Node apps.
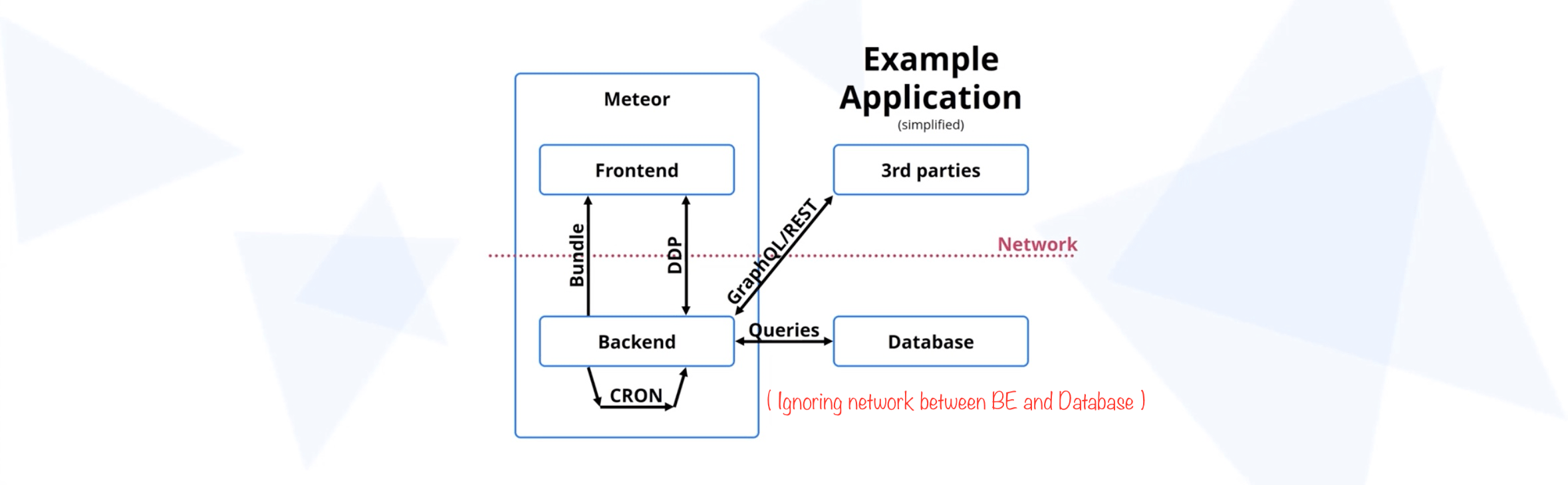
Scopes:
- Initial HTML & bundle size (and it's parsing)
- In-app logicz
- Method & Pubs response time, database queries
- Other APIs



Meteor itself is usually not the bottleneck.
- https://forums.meteor.com/t/meteor-performance-optimizations-summary-as-of-2021/55043/5
- https://www.vazco.eu/blog/how-to-effectively-monitor-the-performance-of-meteor-projects
- https://forums.meteor.com/c/performance/28
Talk focuses on ideas, not specific code/packages.
- consider various regions, data plans
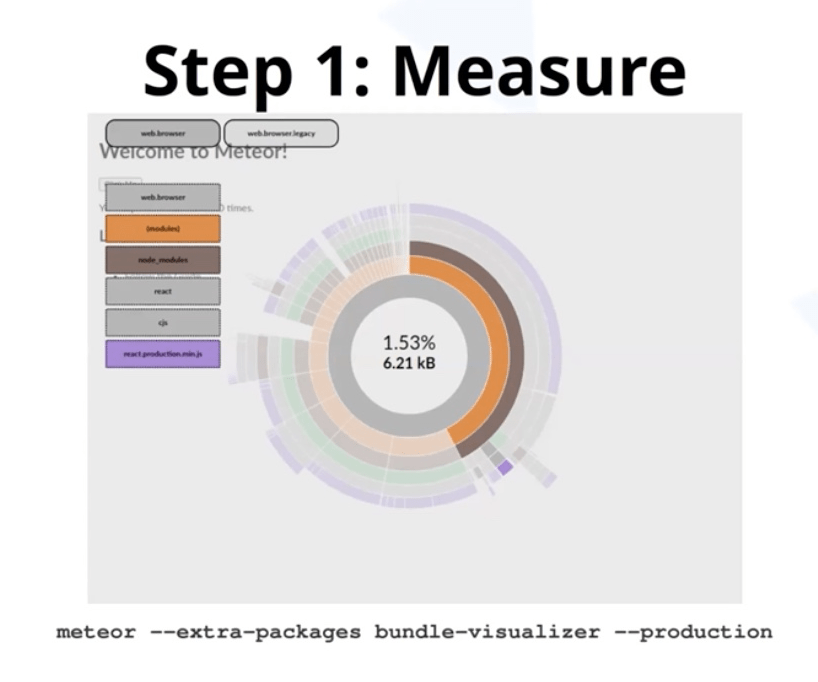
- dynamic imports – code still there, but loaded later, changes dynamics of performance
- smaller dep alternatives
- preact
- date-fns
- lodash-es
- crypto libs
- validation libs (eg. phone number, mime types)
- eliminate dead code
- tree shaking
- PR #11164
- Measure with Lighthouse - metrics based on UX, not tech specs
- First Contentful Paint
- Speed index (time needed for network)
- Largest Contentful Paint
- Time to Interactive – considers parsing JS
- Total Blocking Time – accumulated all above
- Cumulative Layout Shift – considering appearing elements shifting layout (eg. fixed headers)
- Follow Lighthouse guidelines
- Measure with Meteor APM

- Focus on trends/evolution
- Focus on impact on users, not just improving benchmarks (eg. improving the fastest/easiest to improve methods)
this.unblock, especially useful with external services- Reduce number of ops – database op/api call
- Consider delaying ops to batches
- Optimise the code itself, using profiler
- Slightly less detailed aggregation charts

- Check # of simultaneous pubs
- Publish fewer documents
- Extract shared pubs
- Meteor has multiplexor of pubs -> if multiple users subscribe to same document using same query, Meteor will deduplicate the observers and share only one observer
- Use
cult-of-coders:redis-oplog - same as with methods
- REST API, public files (if not using CDN)
- HTTP tab of Monti APM (Meteor APM is not so good yet)
- Use non-Meteor APM
- Apollo Studio (for GraphQL)
- Datadog APM
- Elastic APM
- New Relic APM
- Raygun APM
- Ideally use the one used in by the rest of the company, to correlate
- Log the performance
- Extract metrics/charts from them
- Generic APMs are not designed for these, but it's usually possible with "custom" measurements.
- TIP: Expose them via API and use generic APM. Auth properly!
- Re-consider timing and batching.
- Re-consider scope – smaller often, bigger rarely.
- Offload to "worker nodes" – external micro-services
- Sometimes a MongoDB aggregation is enough, maybe for analytical database with 1h update time. To avoid scattering.
- Use MongoDB Atlas - scary at first, learn to read in them.
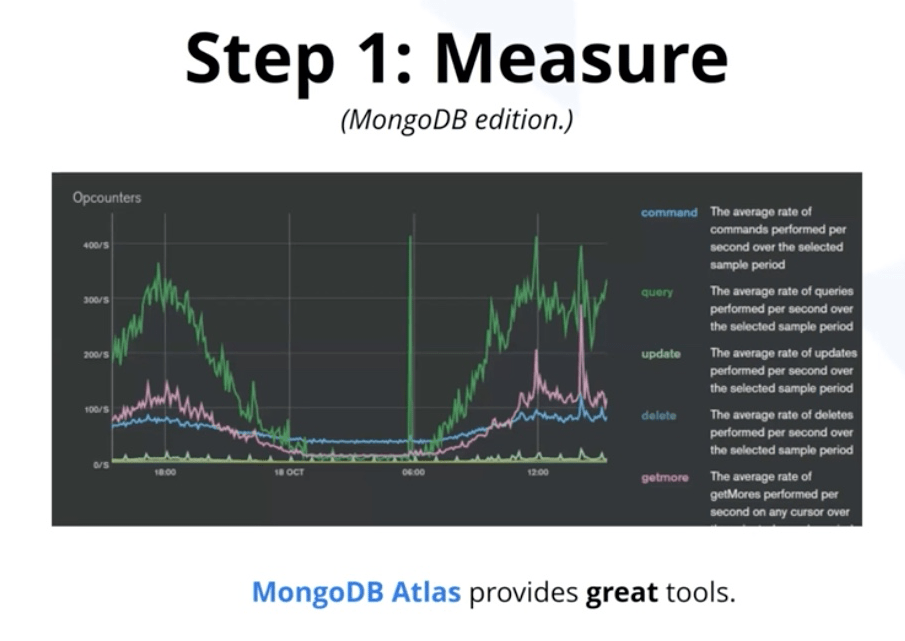
- Check your indexes – remove no longer used ones. Atlas detects it.
- Check RAM usage. Prune old, incorrect data (eg. demo, examples, seed)
- Check queries via
.explain()
- Study perf for both Node.js apps and Web apps – Meteor is both.
- Don't use
unblockblindly. Use APM to check wait time (time to start executing). - MontiAPM at the moment has more features than Meteor APM.
- has HTTP monitoring - useful for REST, but not GraphQL (due to single endpoint)
Guillermo Martinez Espina


The problem – testing Meteor Methods and Publications is not
friendly. Here are some ways to do it.
- Hardcode values – You have to deactivate middlewares for testing as well.
- DDP Tools – Install third-party programs
- Meteor Shell
"Back-end developers should be able to test their endpoints without
having to use the front-end or writing scripts"
Meteorman
- Call methods
- Subscribe to publications and see updates in real time
- Document your endpoints with Markdown
Future (basically what Postman does)
- Cloud service - saving collections
- Shared Workspaces with team
- Load testing
TODO: Recorded demo should be posted
- useMeteorState,
- useSubscribe,
- useFind,
- useUserId
- useUser
Maintainer of useTracker
Why? Tighter integration than just
Collection queries for massive lists - if one changes, whole list re-renders (or at least reconcile). References stay stable (useful for animations)
useTracker.Collection queries for massive lists - if one changes, whole list re-renders (or at least reconcile). References stay stable (useful for animations)
useFind – single cursor from factory method
Plays nice with React logic.

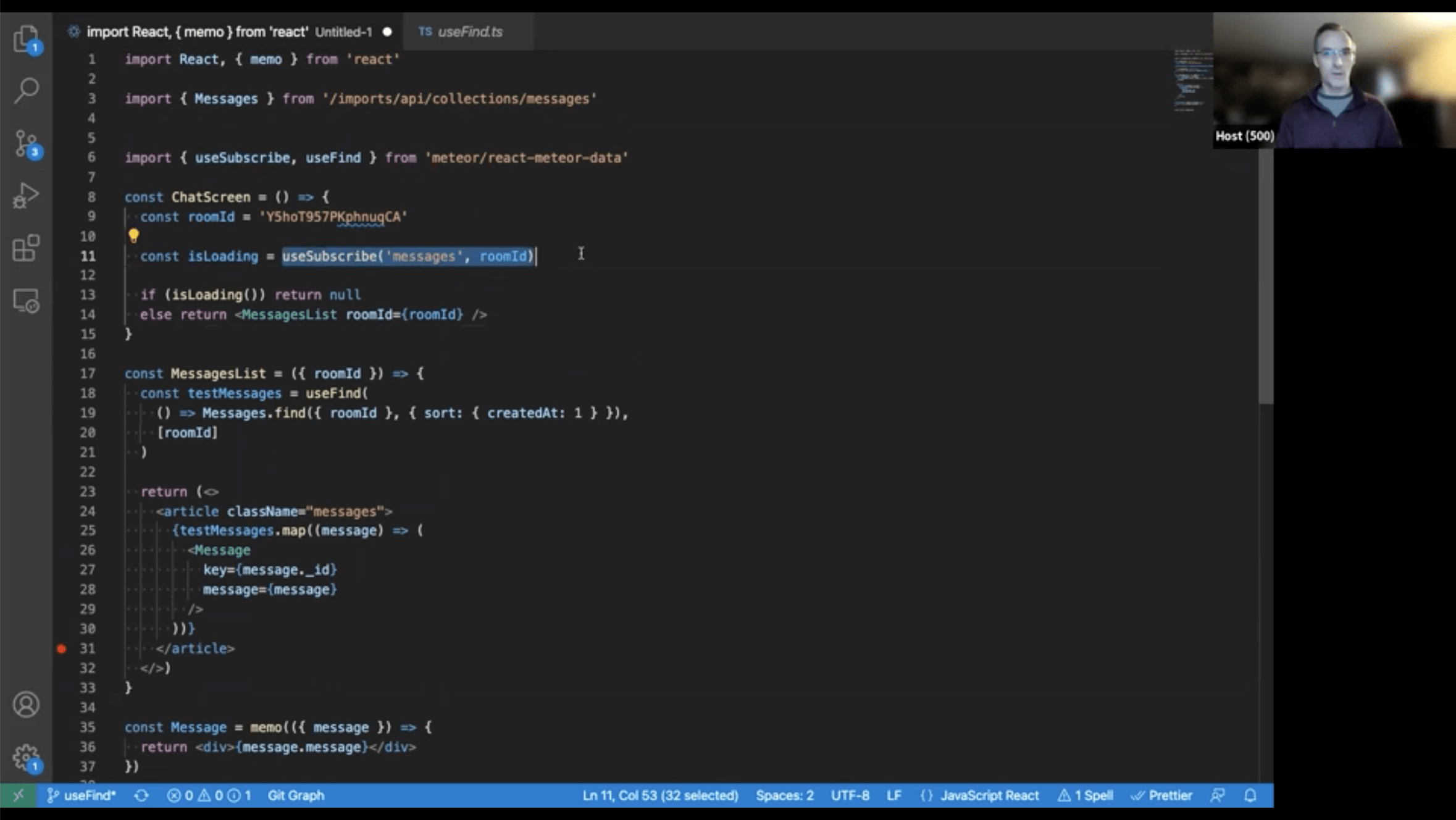
why is isLoading method? To setup reactivity only when needed loading indicator.
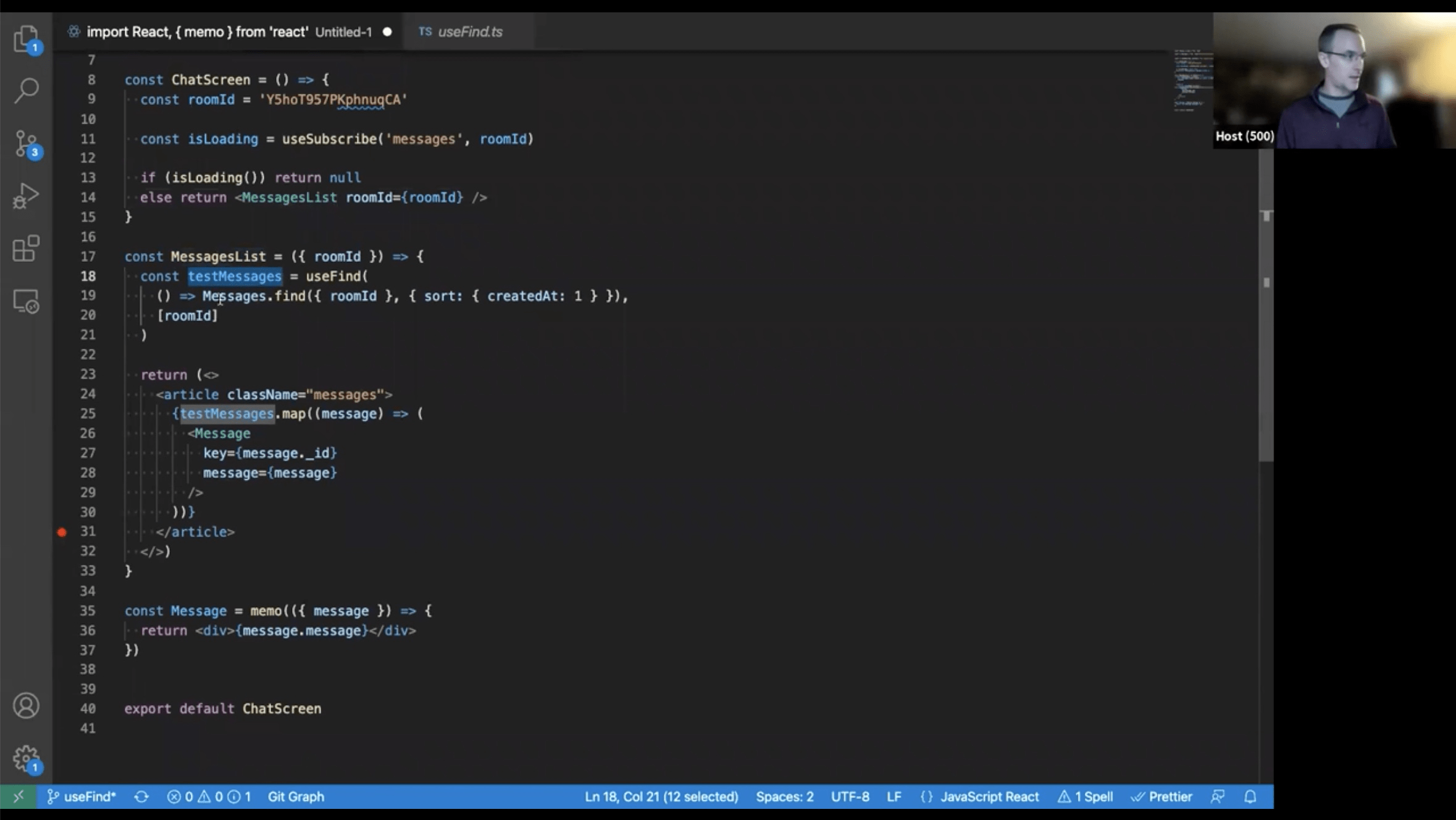
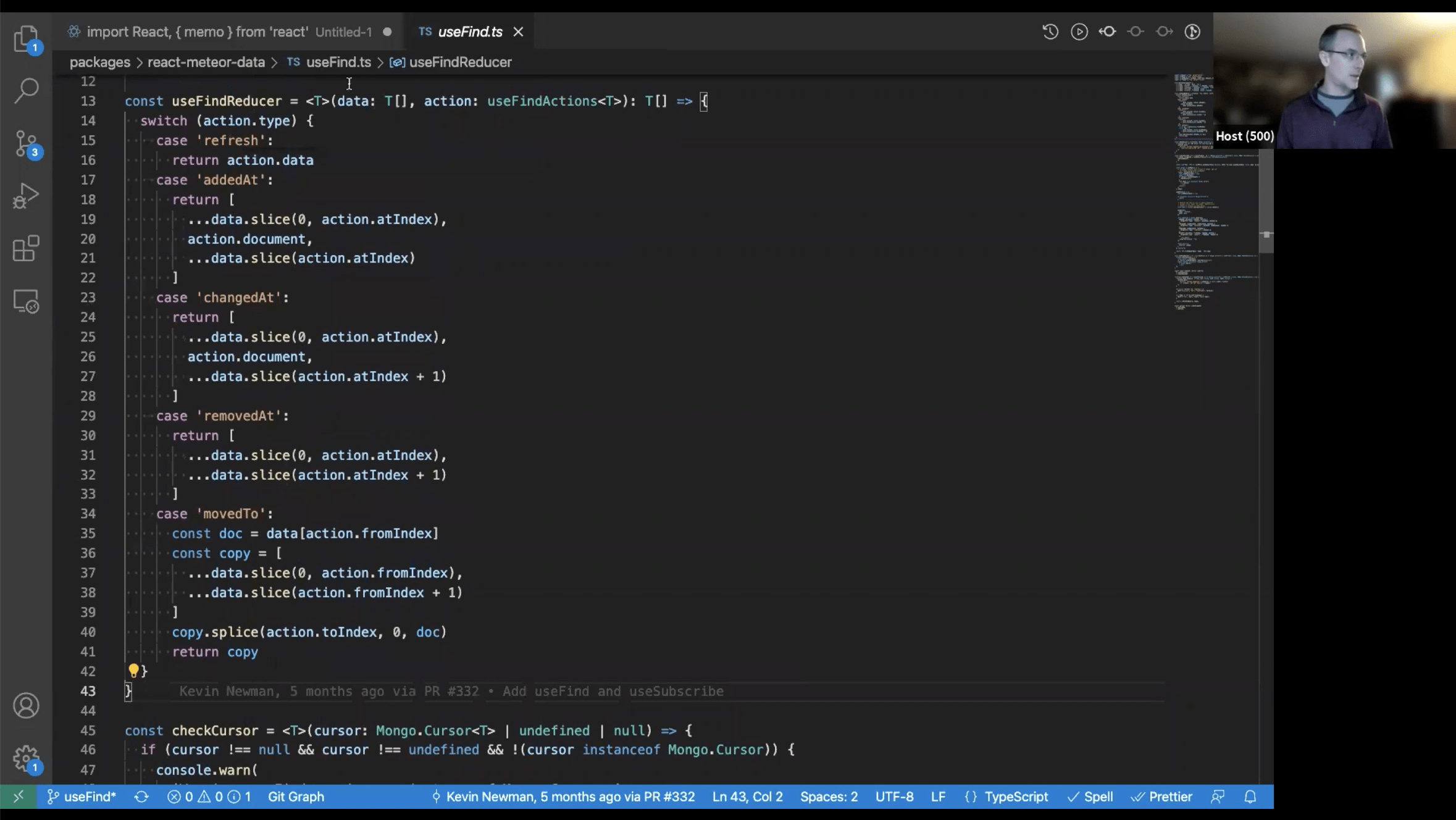
Use cases: Chats, big tables.

Plays nice with React logic.
why is isLoading method? To setup reactivity only when needed loading indicator.
Use cases: Chats, big tables.
Many small components - optimised for concurrent mode.

skipUpdate - compare results by yourself.
Beware:
Useful when your backend provide update timestamp.
Beware:
fast-deep-equals can be actually slower than React
reconciliation. You are basically skipping React optimization.Useful when your backend provide update timestamp.

just simple convenience wrappers

requires globally unique id, unlike useState
Option to opt-out
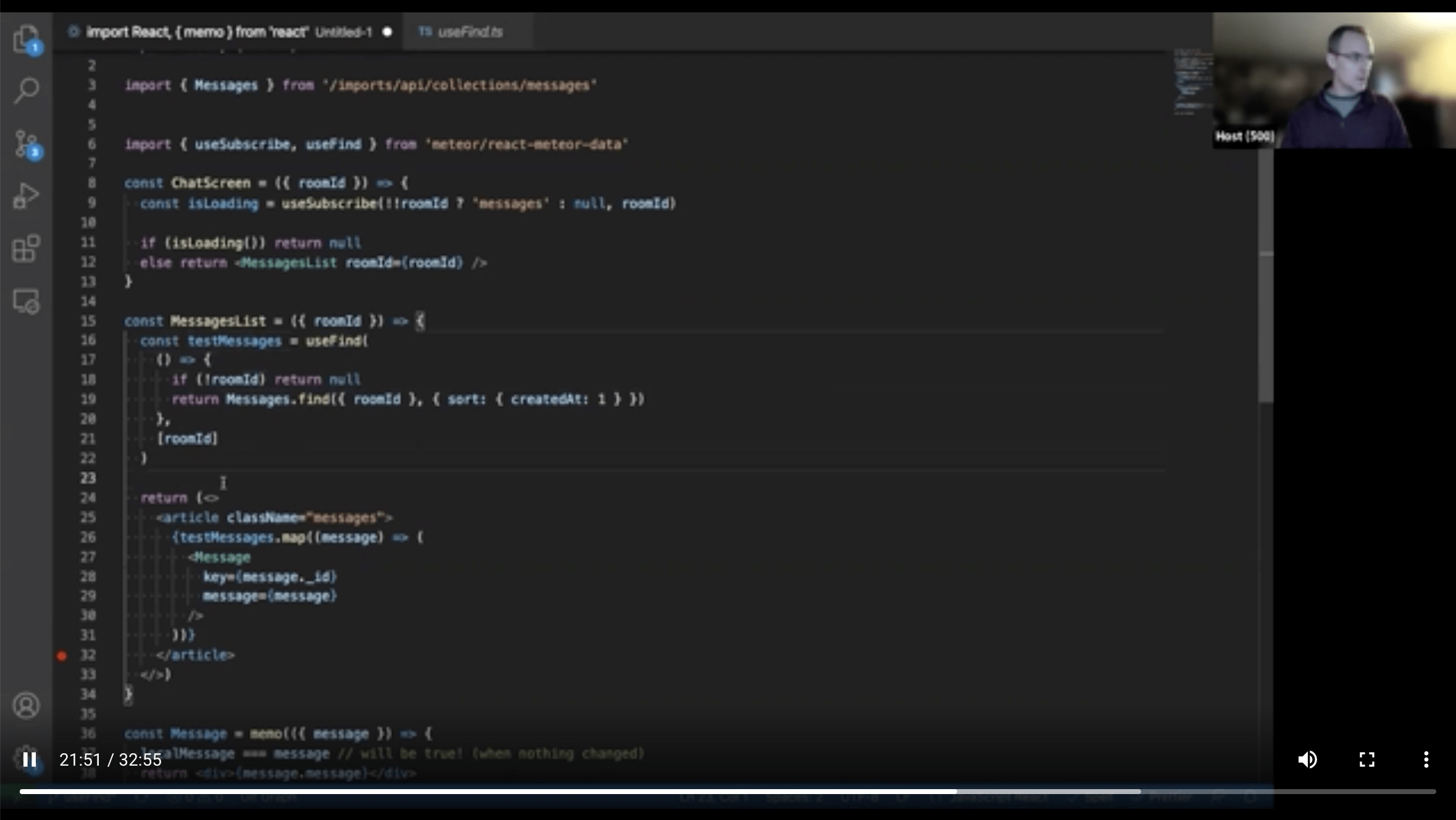
findOne - use useTracker(), internally just
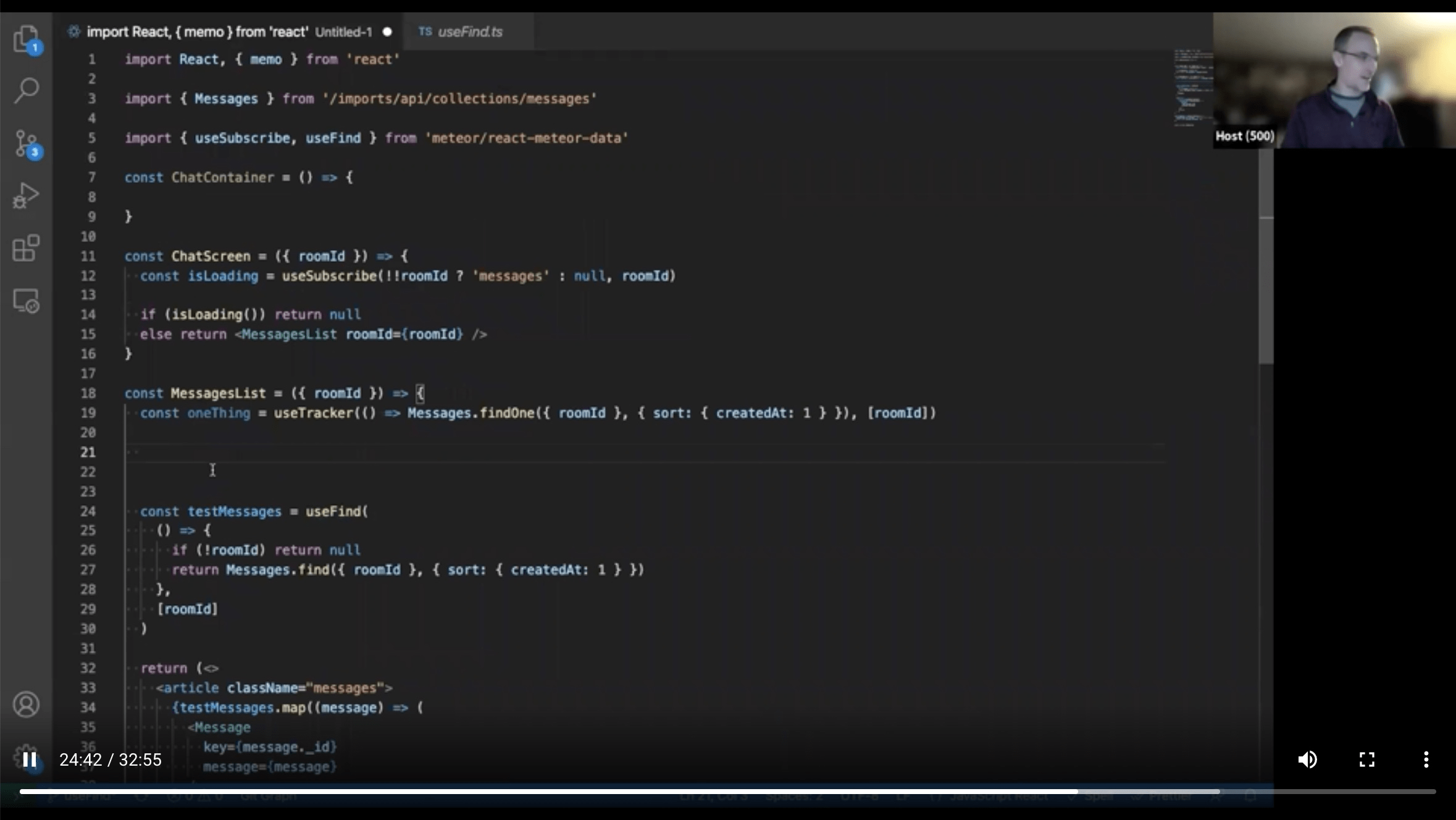
findOne - use useTracker(), internally just
.fetch()[0], so no special
hook necessary. Don't use useFind as it creates cursor.Diff between
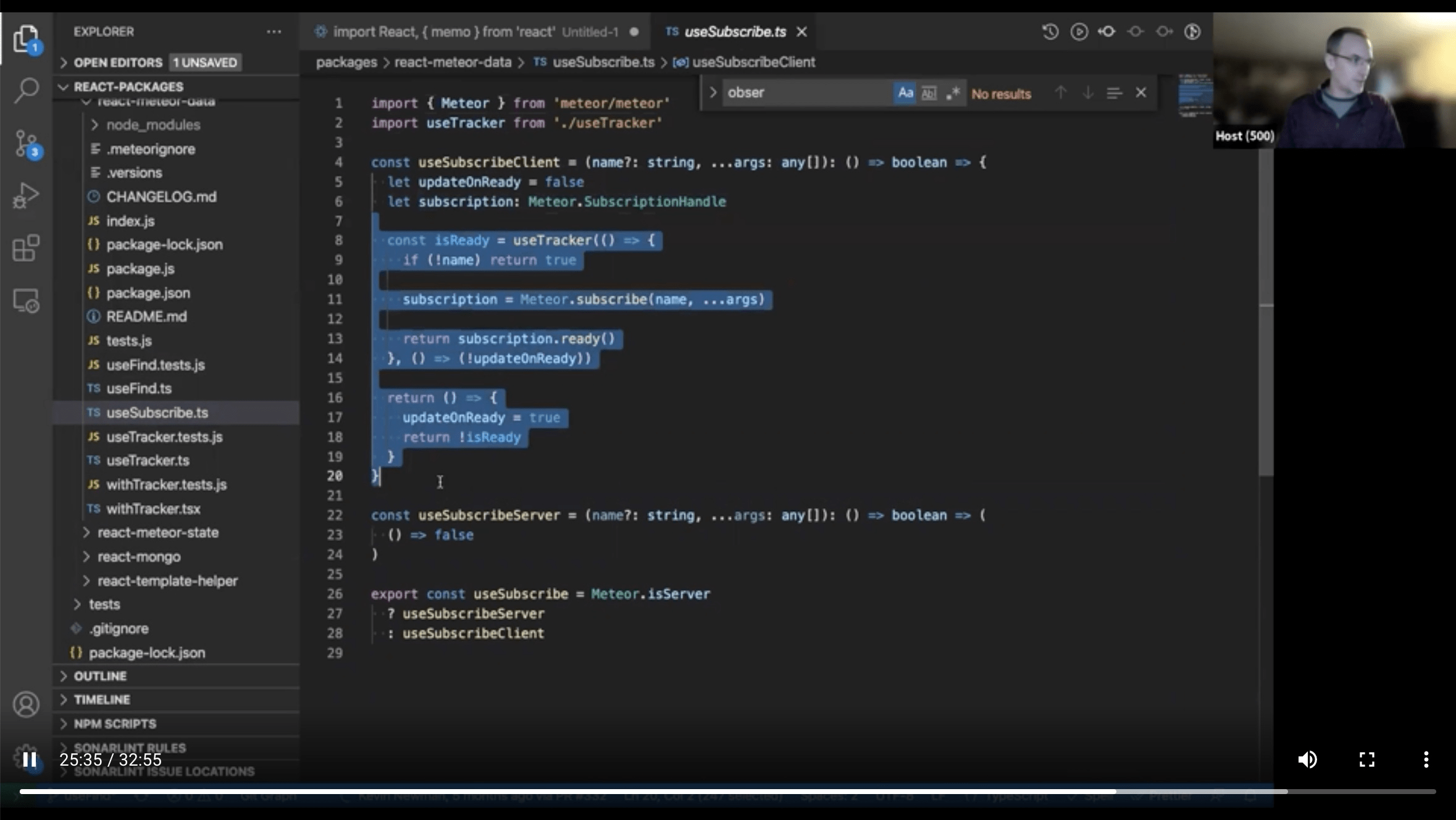
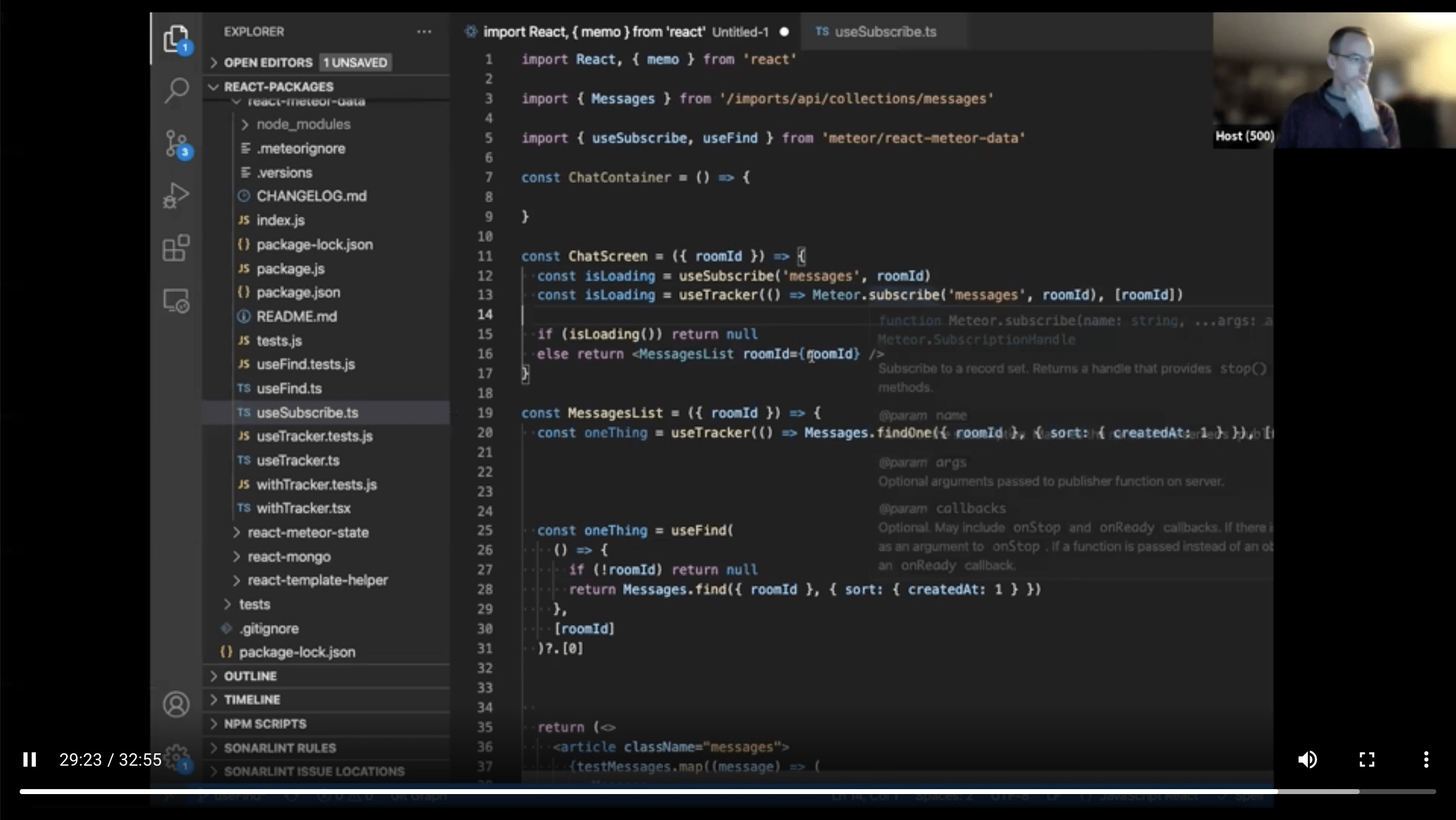
useSubscribe and subscribing in useTrackerhttps://github.com/meteor/react-packages/tree/useFind/packages/react-meteor-data
https://github.com/meteor/react-packages/blob/useFind/packages/react-meteor-data/README.md
https://github.com/meteor/react-packages/blob/useFind/packages/react-meteor-data/README.md
skipUpdate can be useful to filter out updates that come from properties
to which you haven't subscribed. It's a quirk of tracker that any
property update will cause a reaction, even if that property is filtered
out in the query itself!
EJSON comparison for subs
https://github.com/meteor/meteor/blob/dae7af832d08a8b19384ac19aa5a5a9b6b005e55/packages/ddp-client/common/livedata_connection.js#L386
https://github.com/meteor/meteor/blob/dae7af832d08a8b19384ac19aa5a5a9b6b005e55/packages/ddp-client/common/livedata_connection.js#L386
~Renan Castro
https://twitter.com/renanccastro?lang=en
https://medium.com/@renanccastro
https://forums.meteor.com/u/renanccastro/summary
https://twitter.com/renanccastro?lang=en
https://medium.com/@renanccastro
https://forums.meteor.com/u/renanccastro/summary

Story about adding chart (and lib) to your project.
echarts 1MB minified, 6s load time on 3g
echarts 1MB minified, 6s load time on 3g

POST
__meteor__/dynamic-import/fetch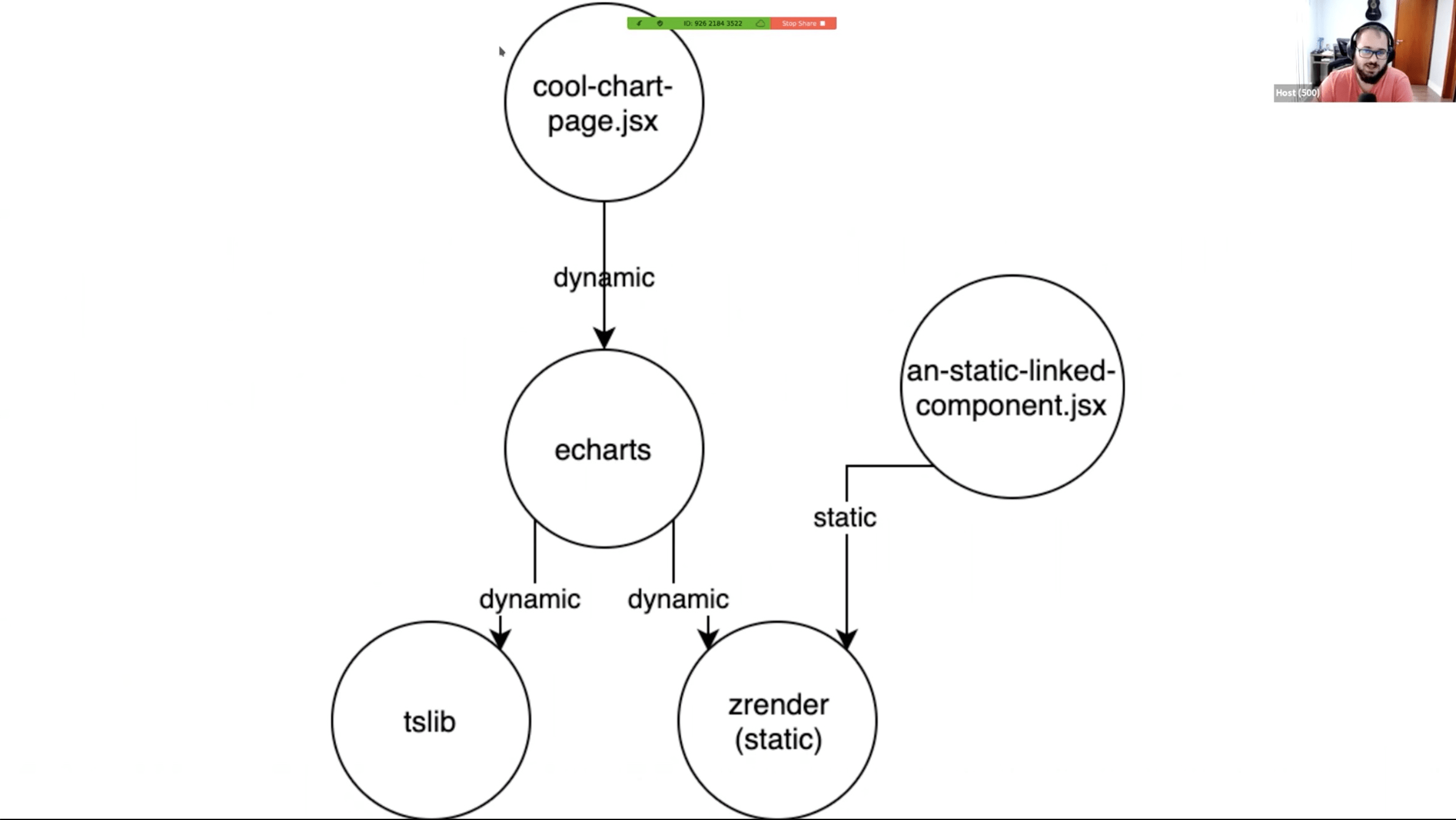
zrender will be bundled.
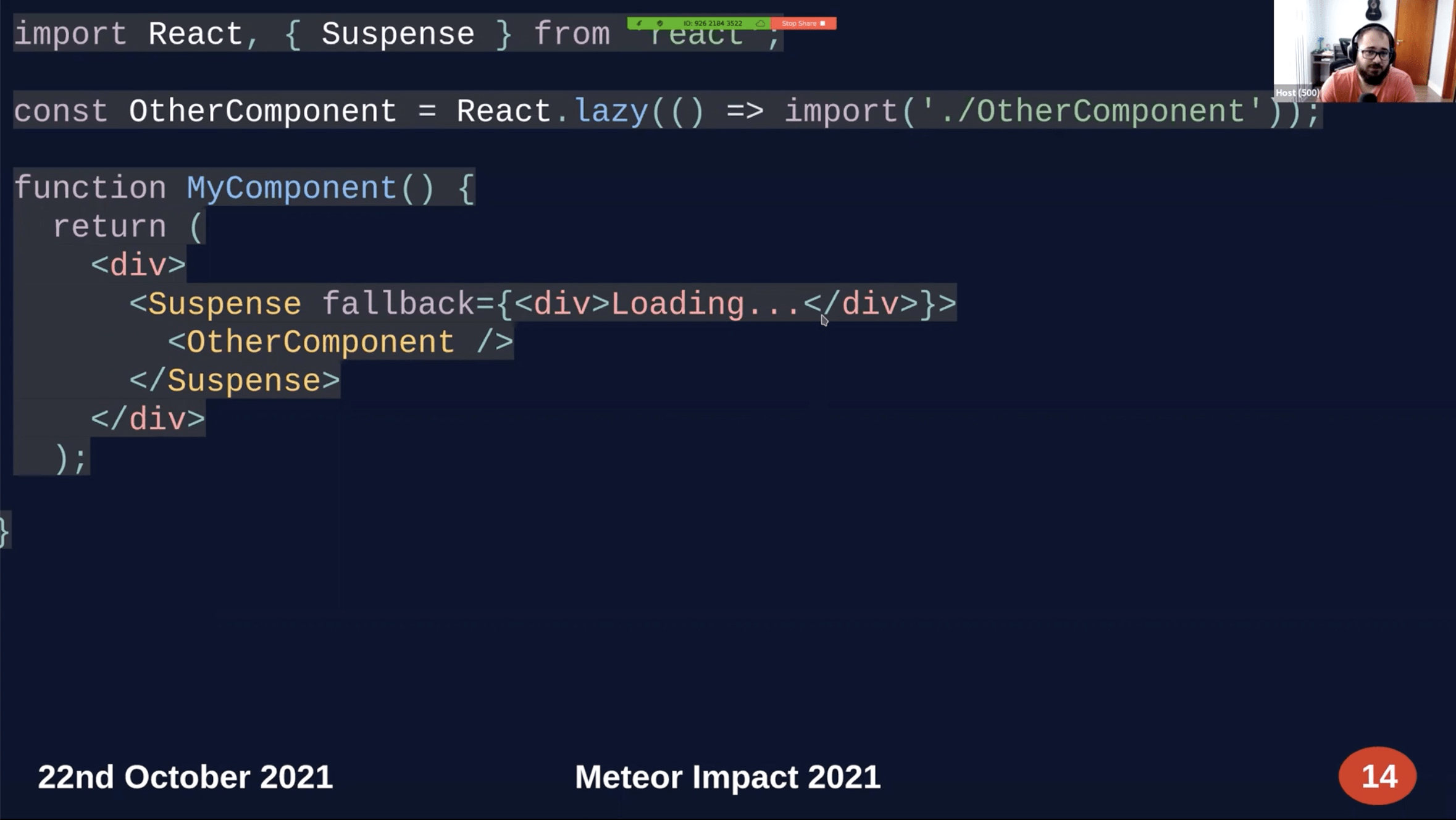
import will return promise.
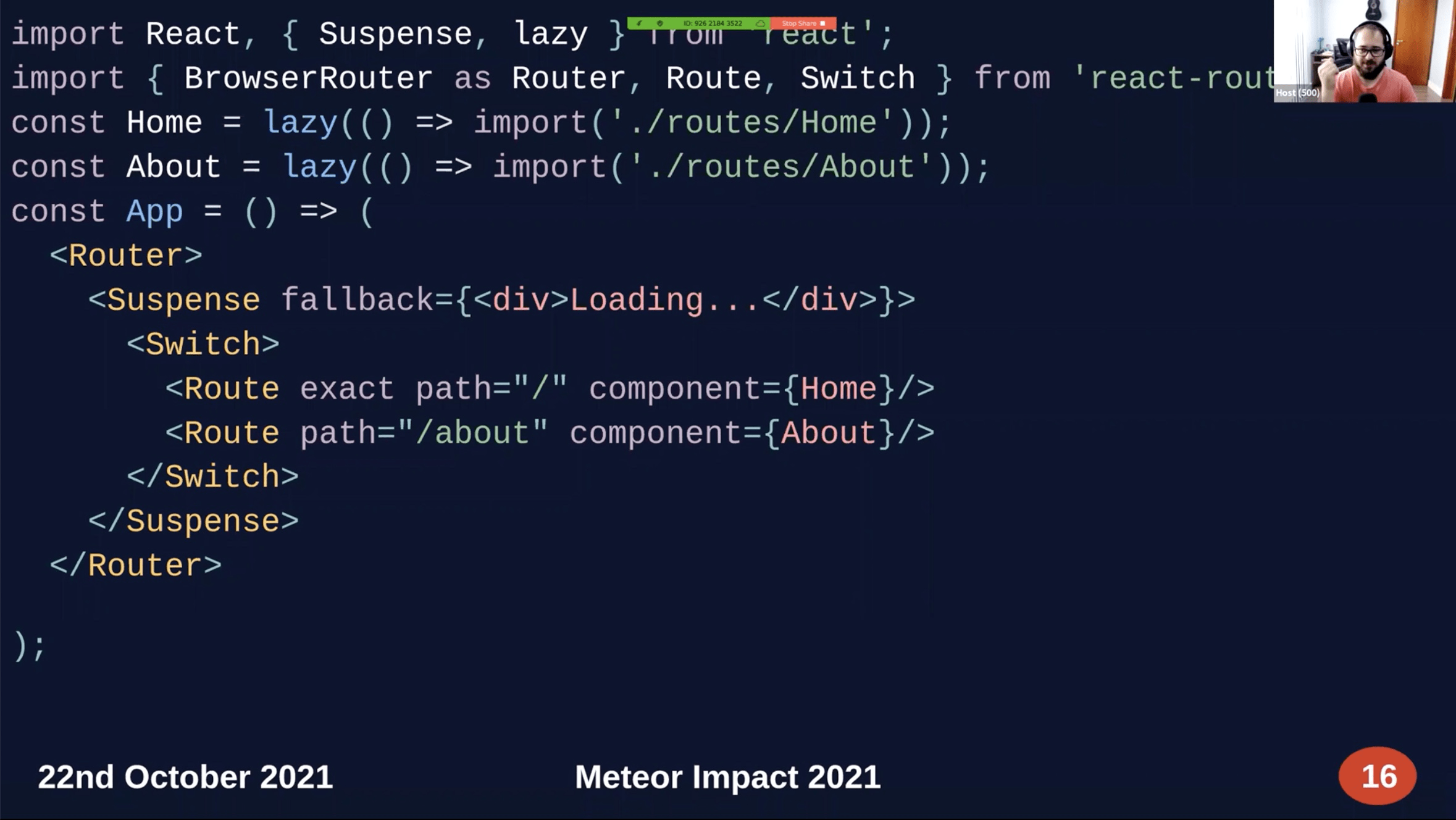
React.lazy currently only support default export.
Frederico Maia
https://github.com/fredmaiaarantes
https://github.com/fredmaiaarantes


Jan Dvořák
https://forums.meteor.com/u/storyteller
https://forums.meteor.com/u/storyteller
https://github.com/meteor/meteor/tree/devel/packages
https://github.com/meteor/meteor/tree/devel/packages/accounts-base
https://github.com/meteor/meteor/tree/devel/packages/accounts-base






override email settings completely


https://github.com/meteor/meteor/discussions/11653
https://github.com/meteor/meteor/discussions/11514
More interesting packages
https://github.com/quavedev/definitions
https://github.com/quavedev/accounts-passwordless-react
https://github.com/quavedev/performance-audit
https://github.com/quavedev/apple-oauth
https://github.com/quavedev/meteor-login-token
https://github.com/quavedev/profile
https://github.com/quavedev/definitions
https://github.com/quavedev/accounts-passwordless-react
https://github.com/quavedev/performance-audit
https://github.com/quavedev/apple-oauth
https://github.com/quavedev/meteor-login-token
https://github.com/quavedev/profile



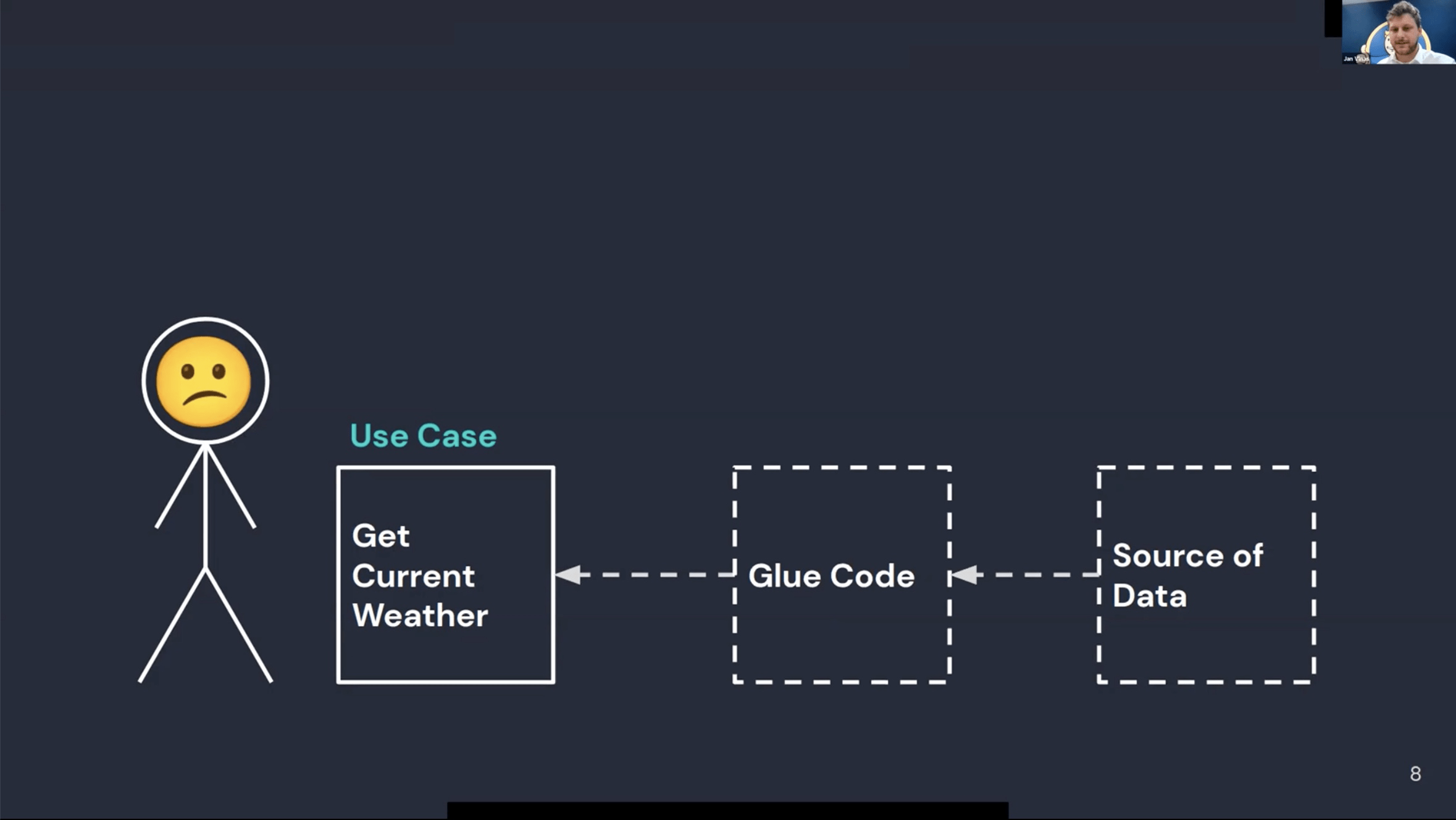
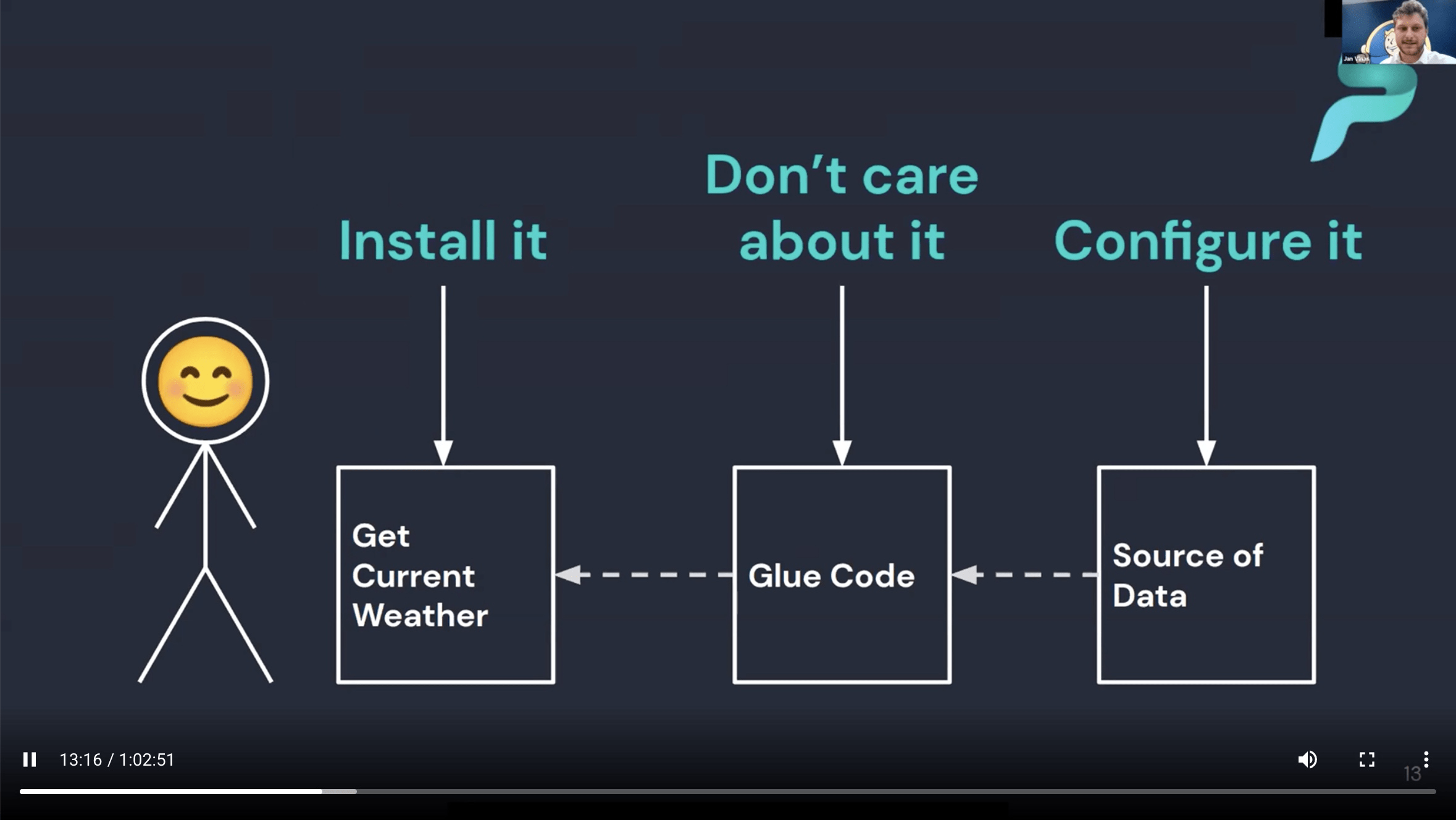
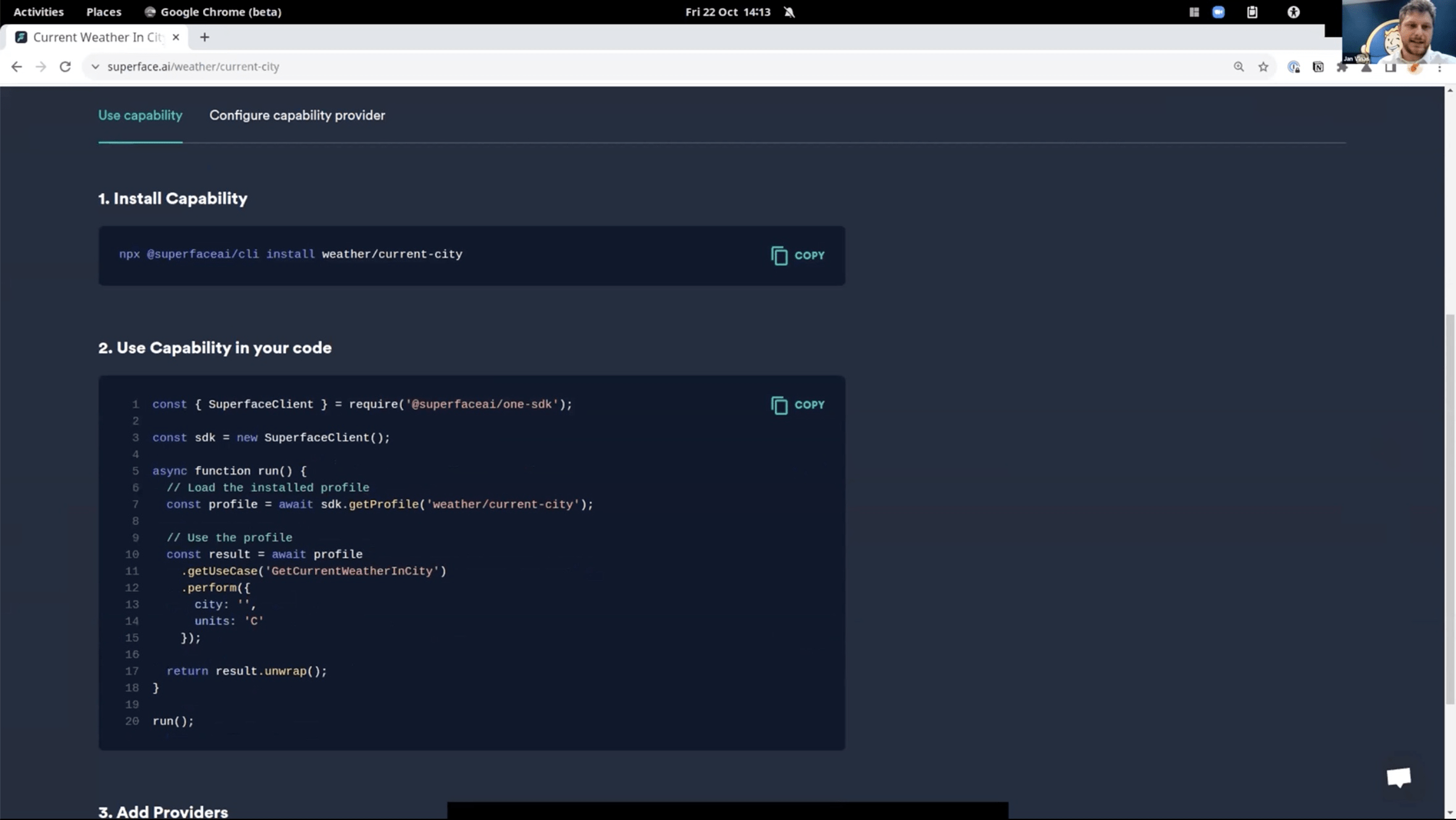
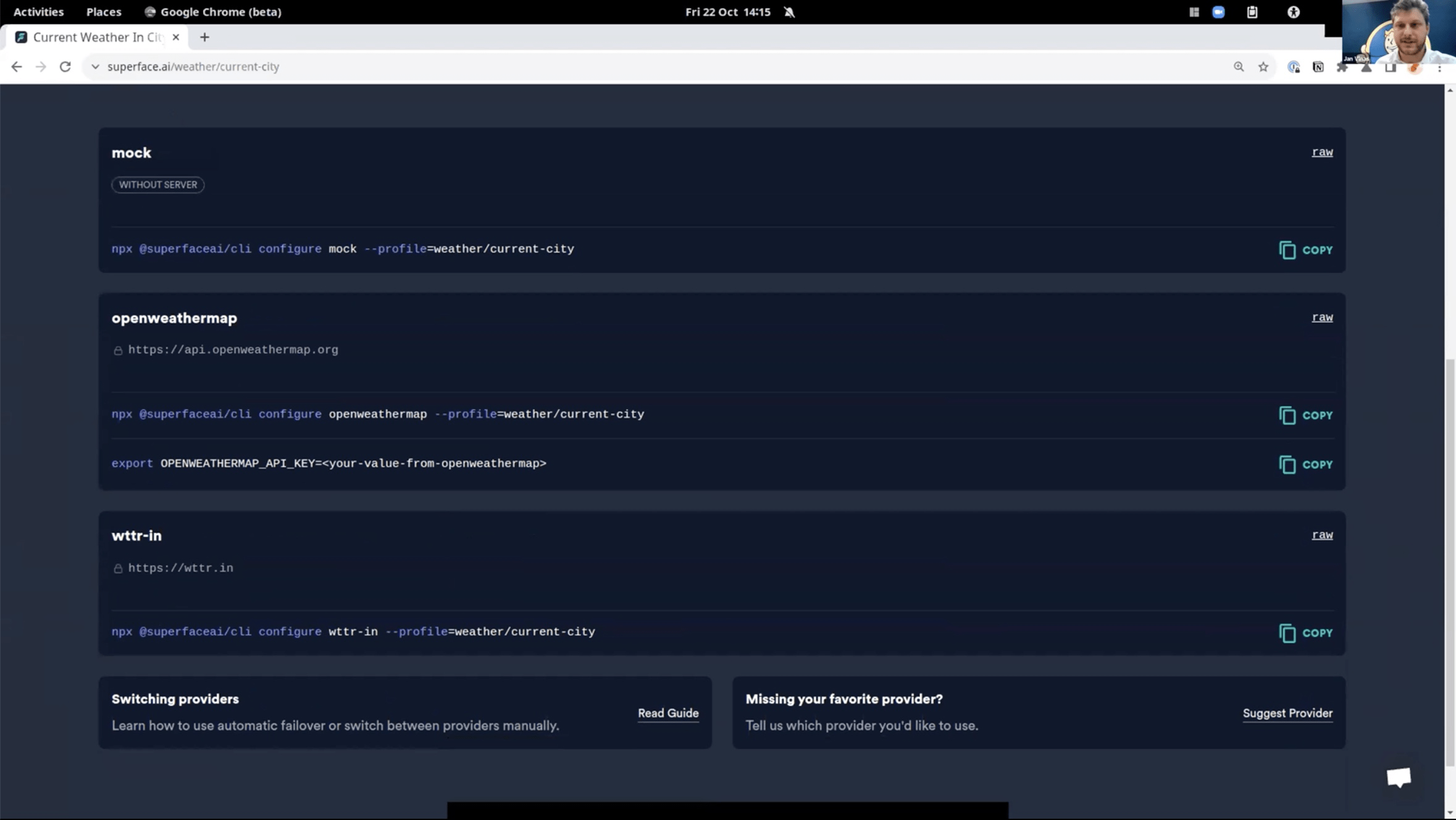
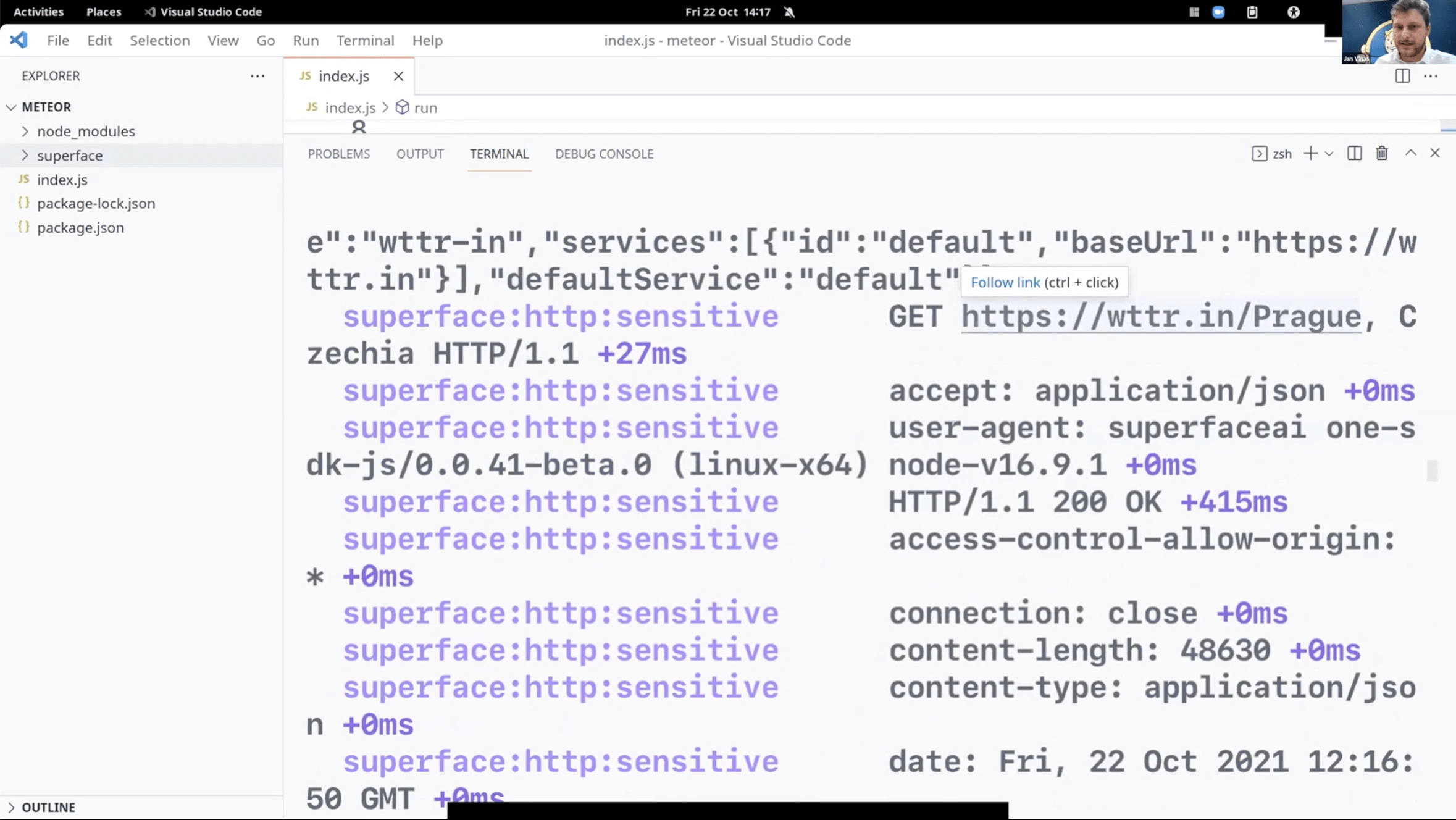
Superface is not acting as a Proxy, traffic goes directly to the service.

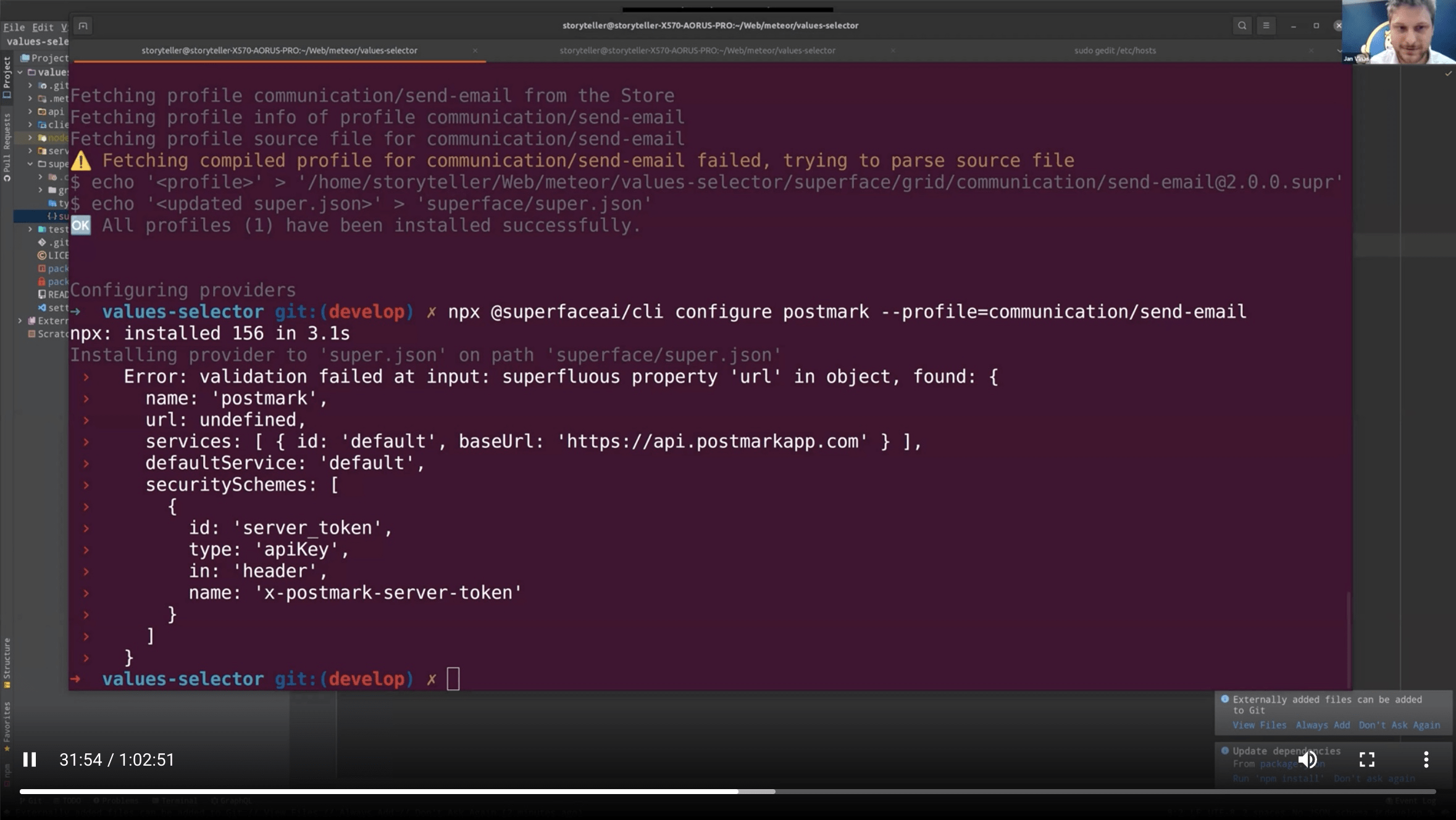
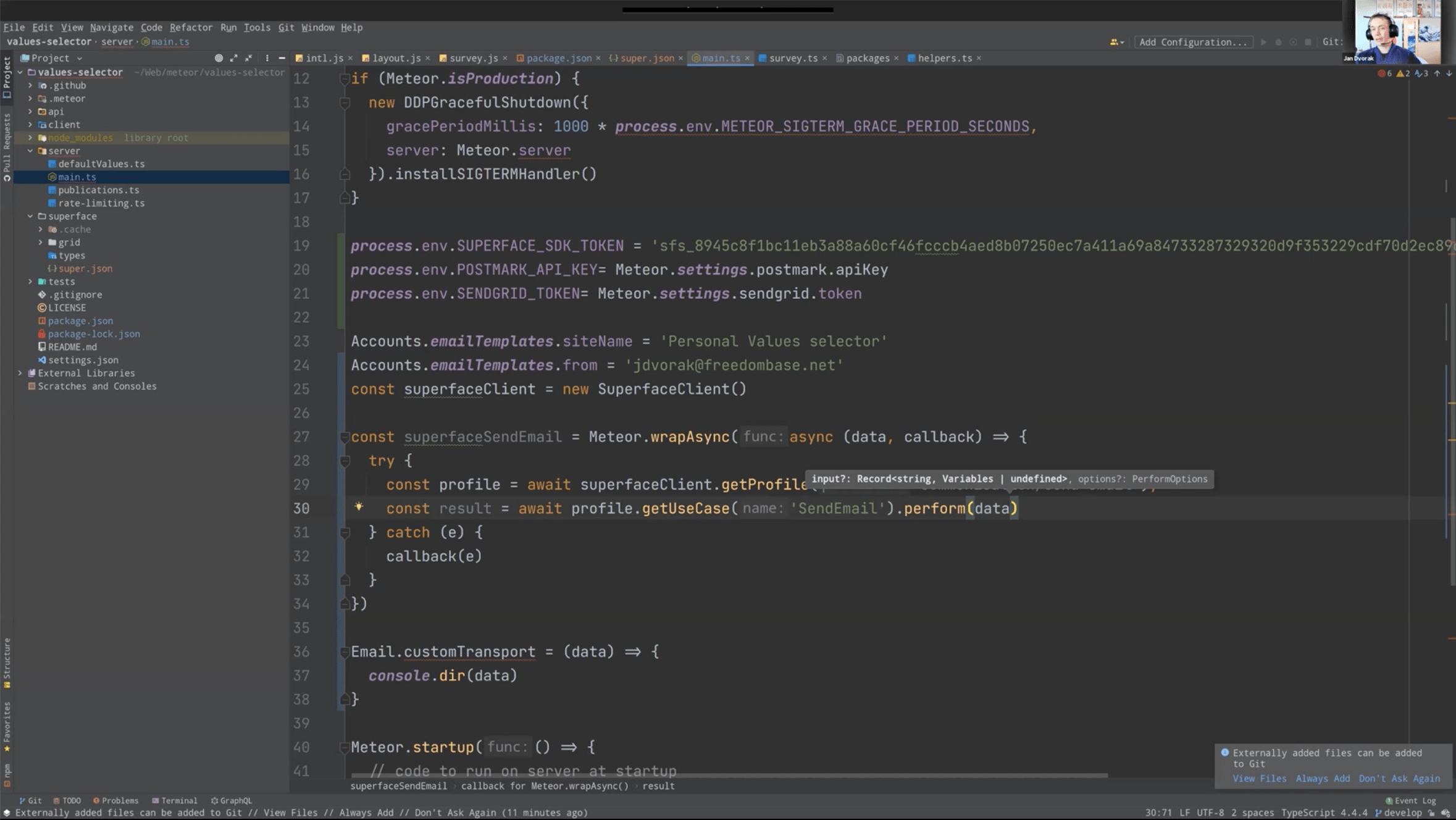


All examples from previous real tests.








^ not owner of this file


^ Upload policy & signature
^ Upload directly to cloud storage


-> always test all the params, especially when more are connected
together.










^ or npm-audit







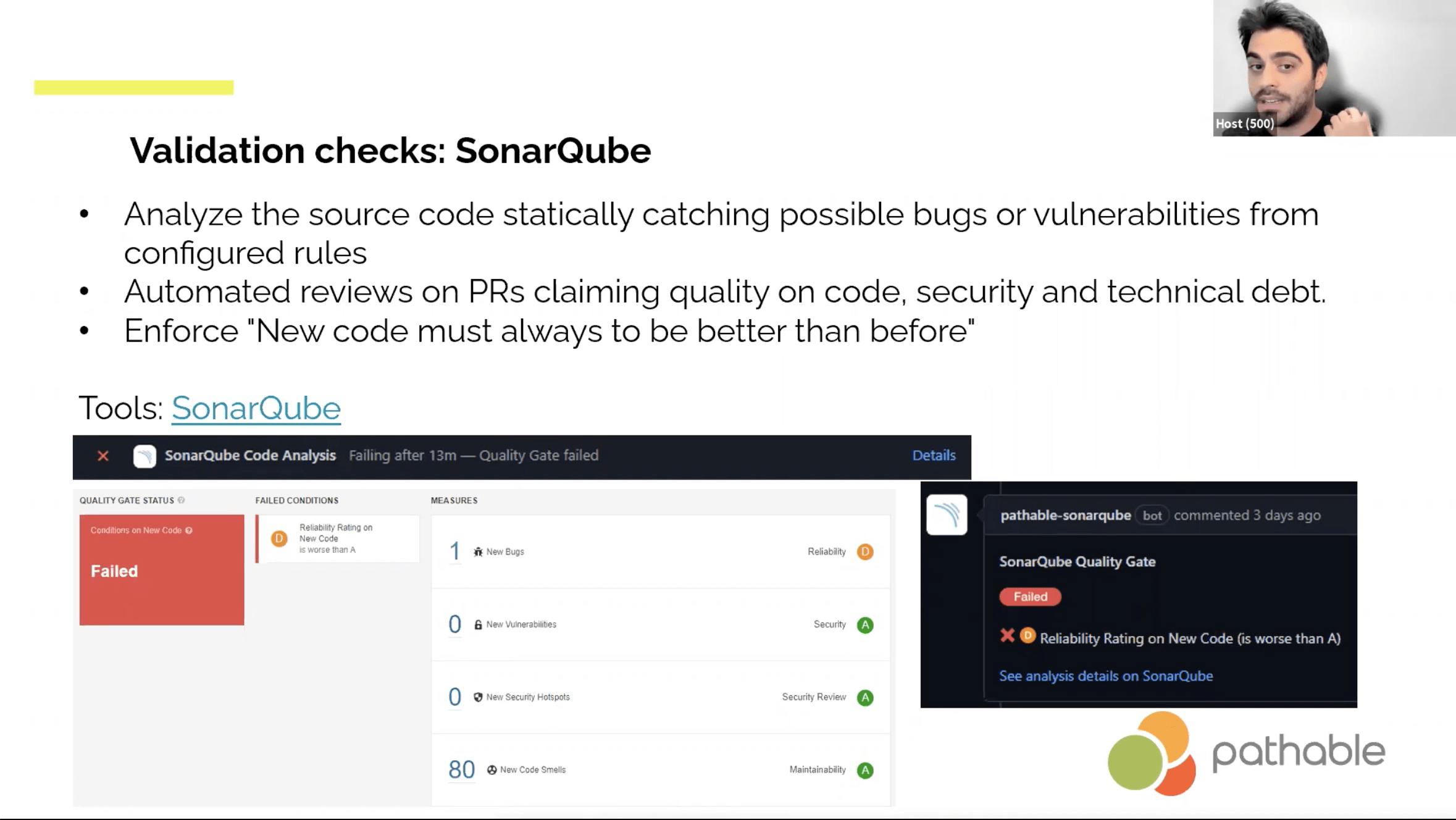




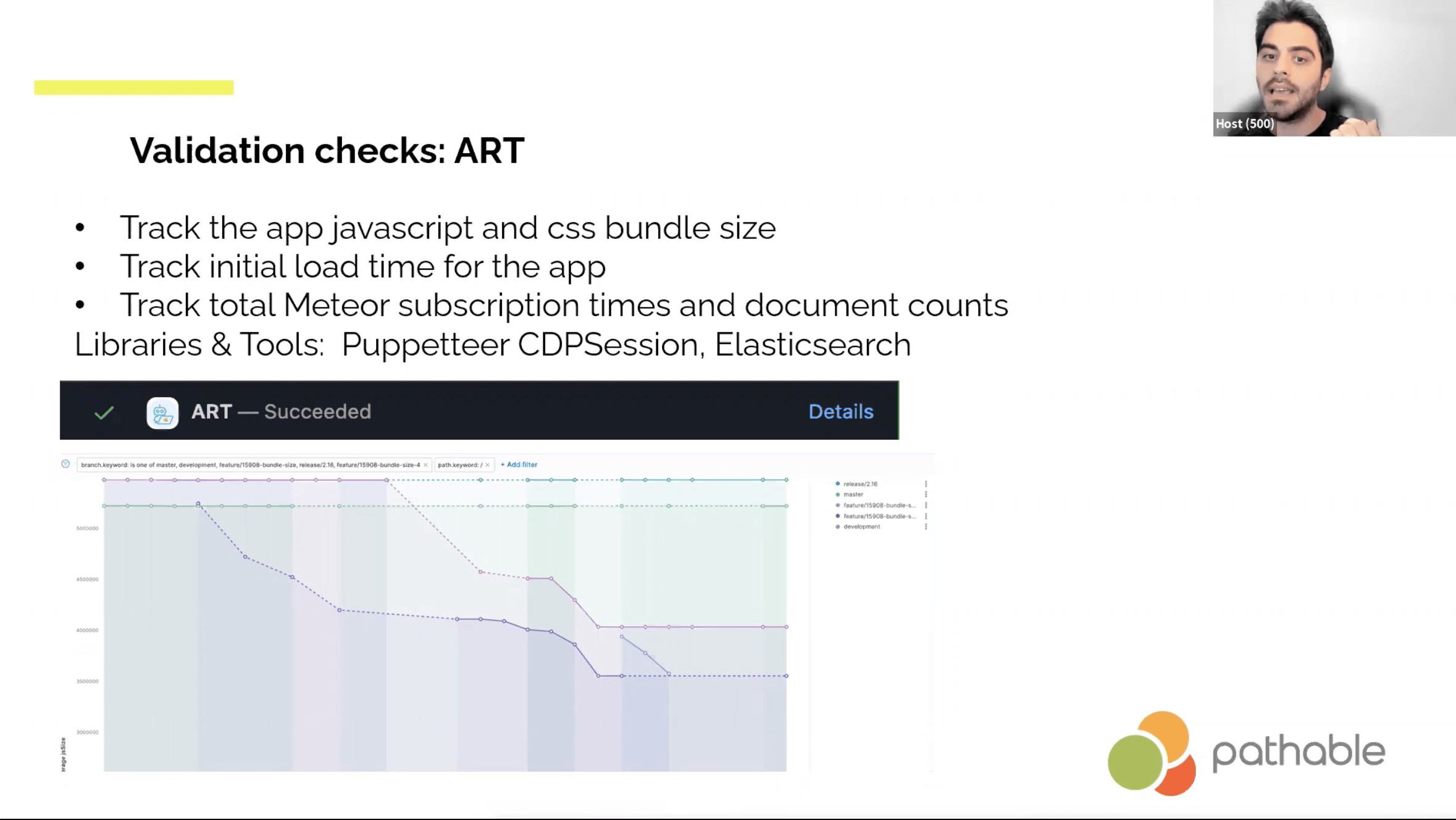

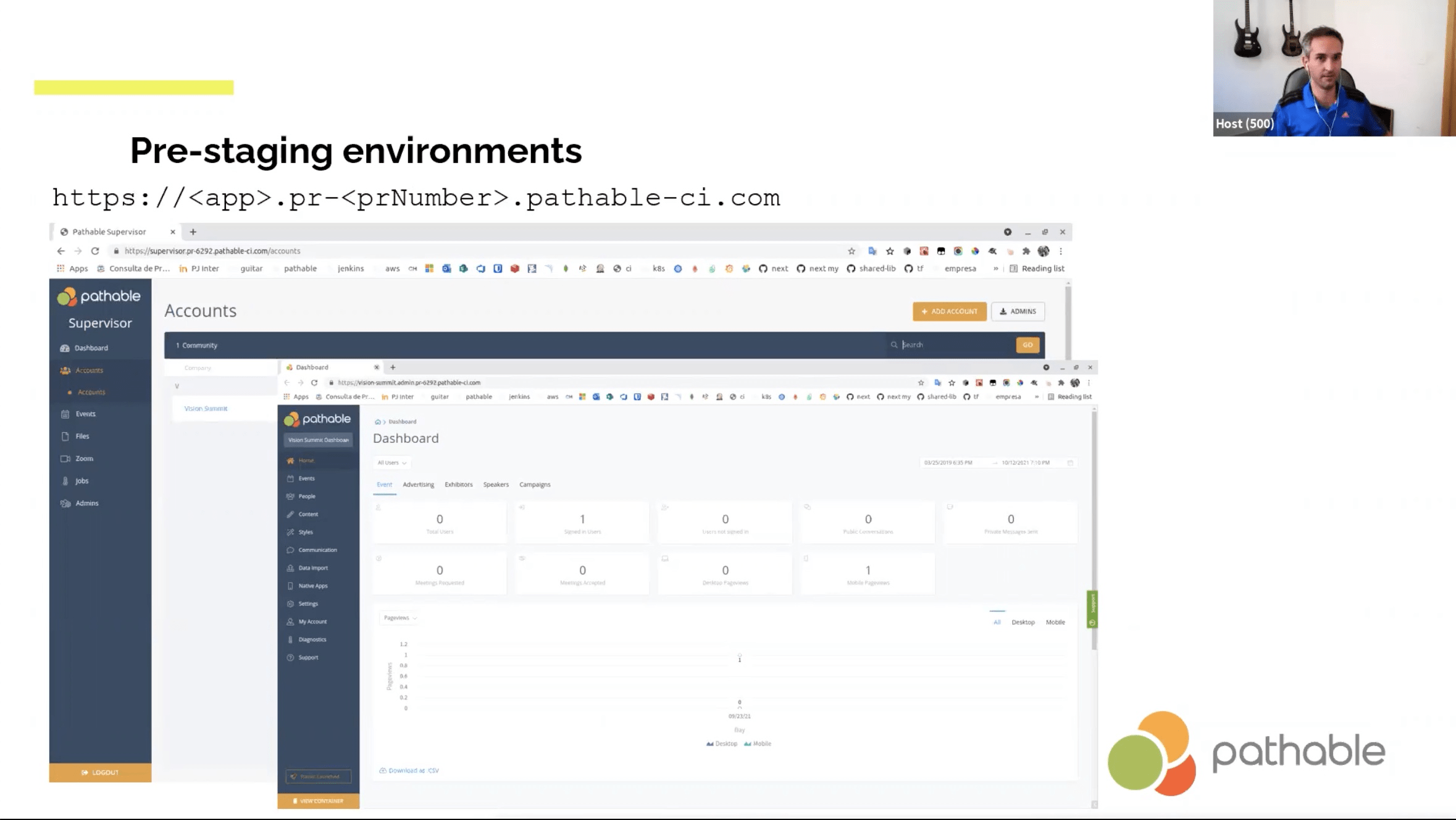
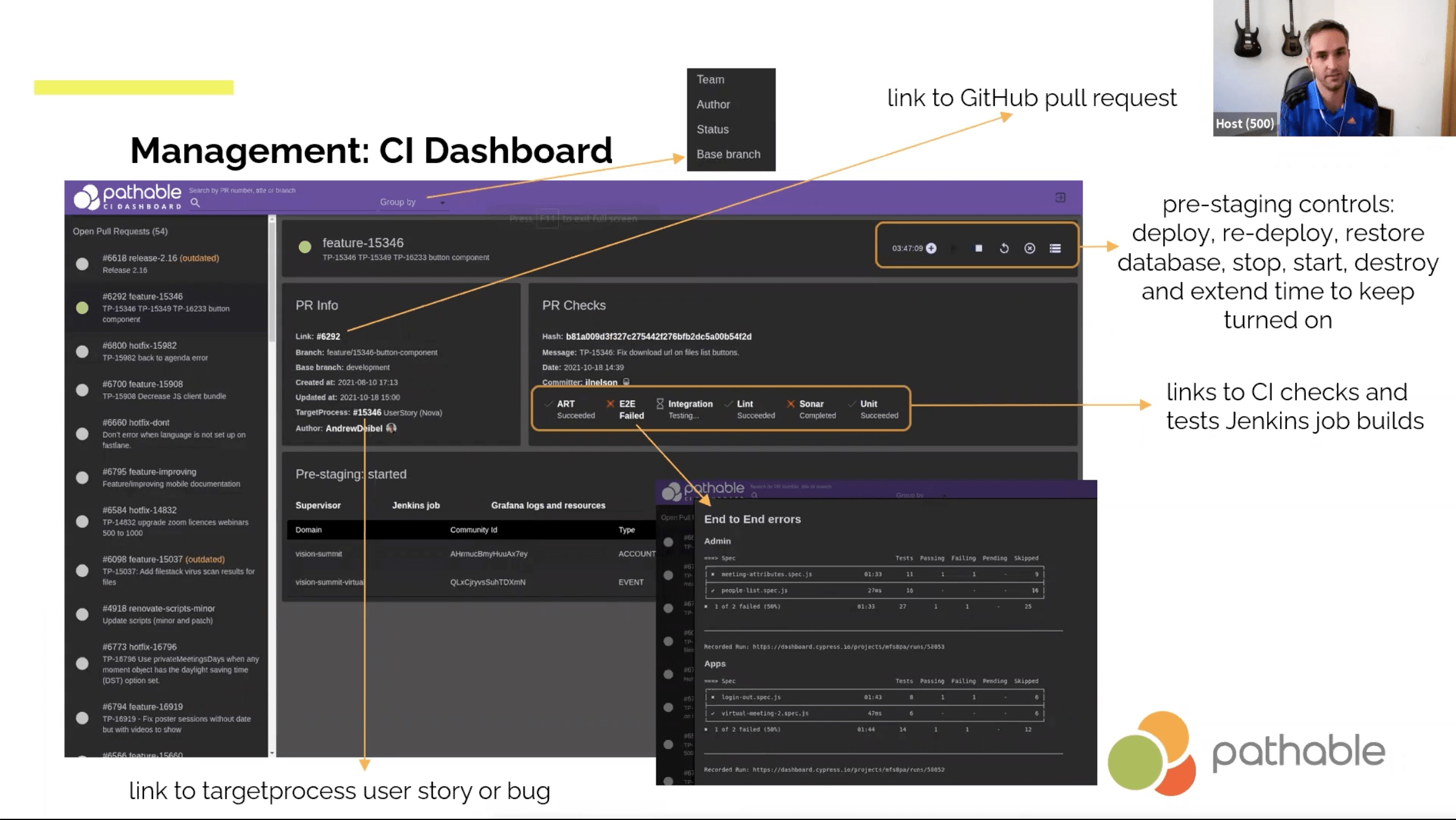


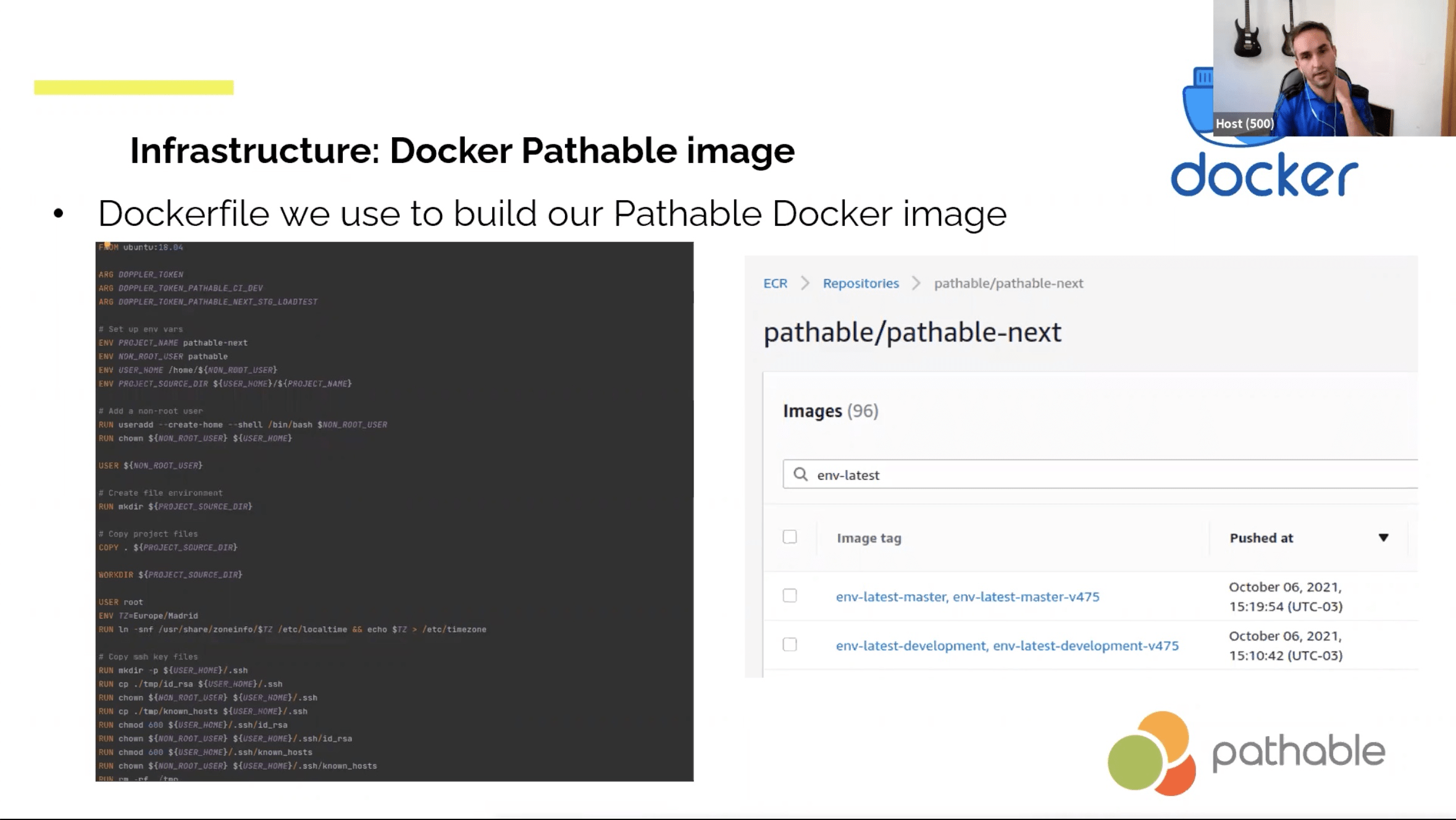



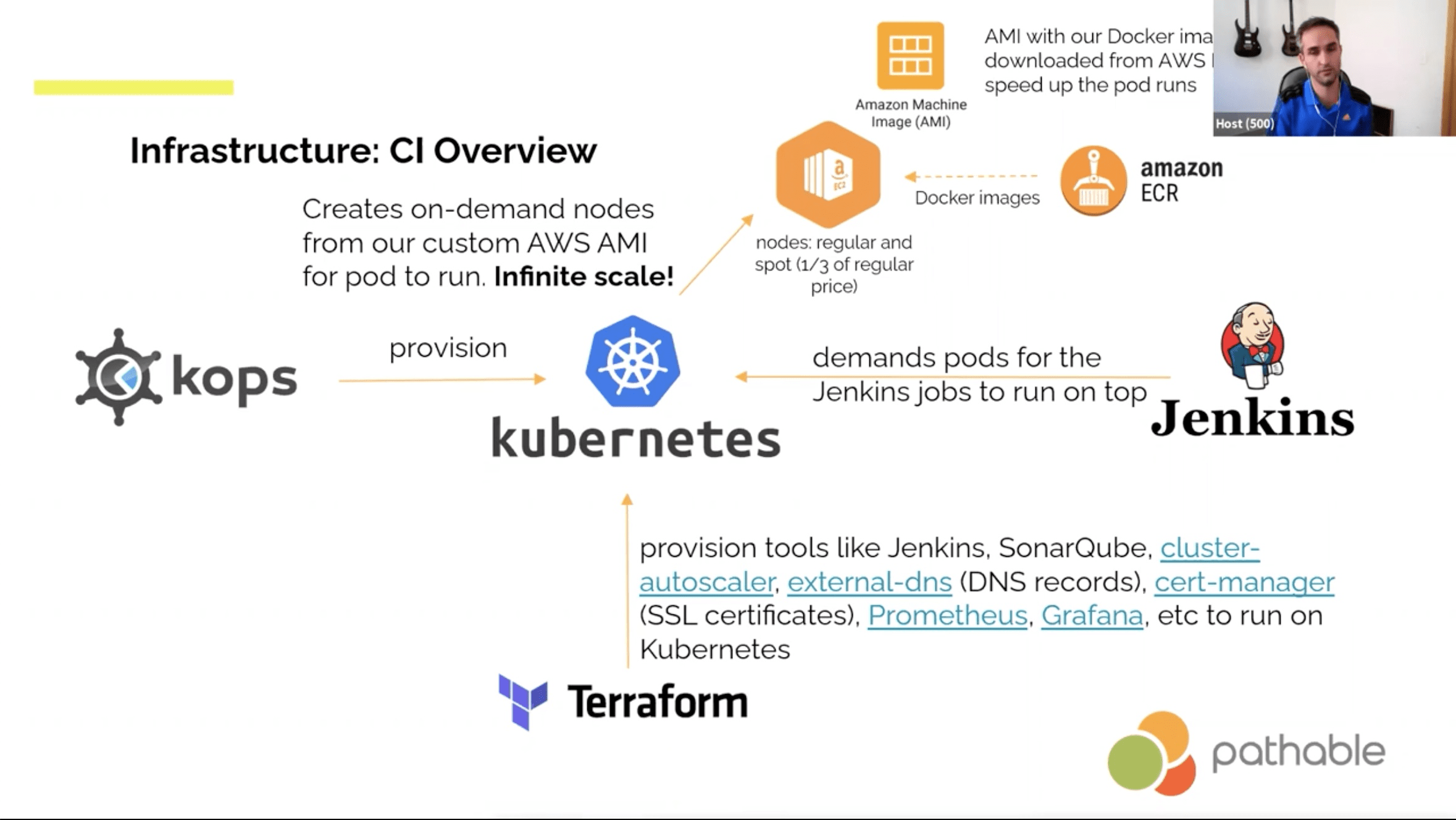
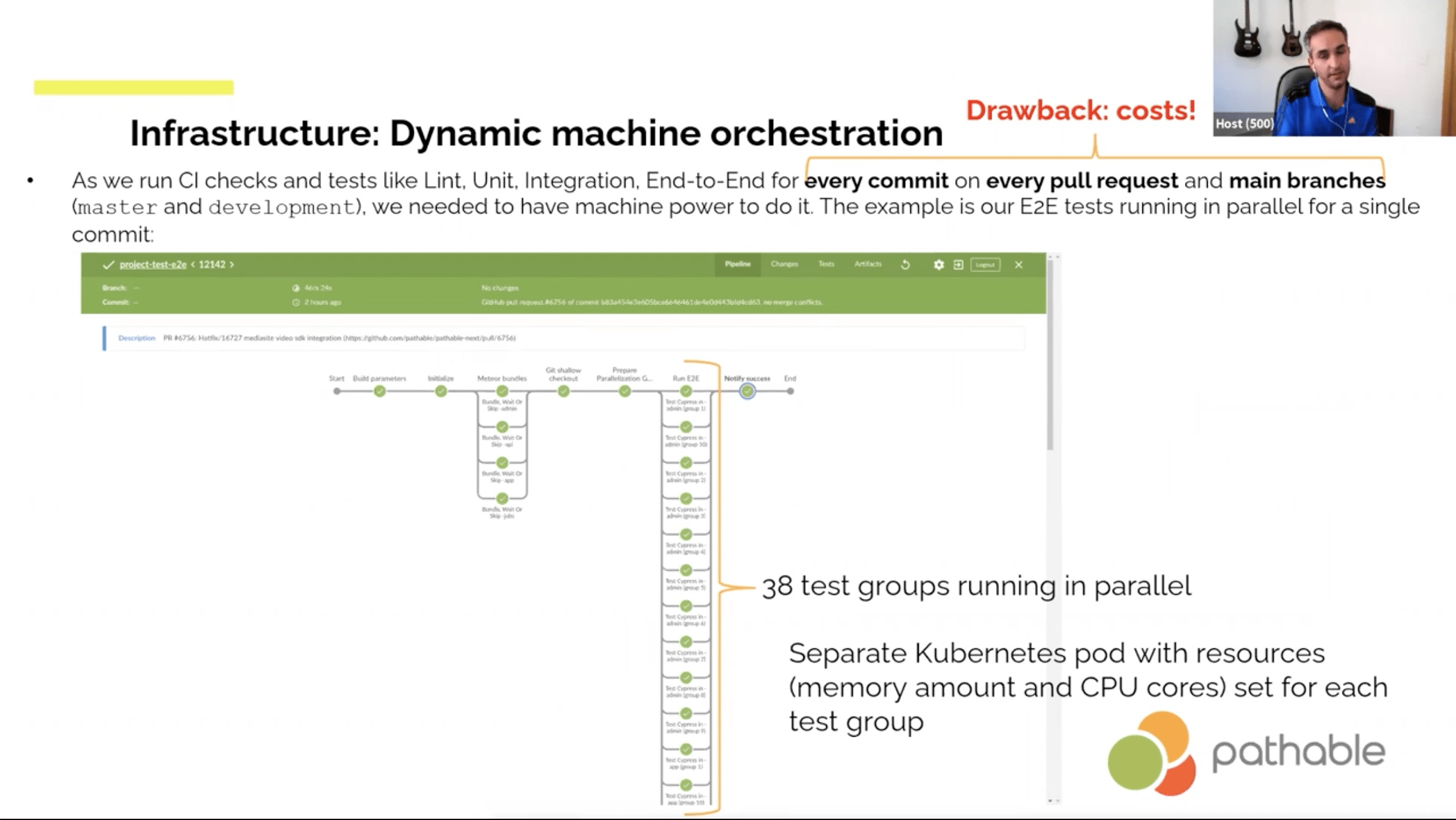
- Jenkins listening to GitHub
- Automated merging and Slack notifications about conflicts